这里是科研人的「方法急救站」!🚑
- • 欢迎加入我们的**"学术社群"**,每日更新热点论文复现指南!
 论文卡片
论文卡片
我们通过小程序科研零时差追踪到: Journal of Cleaner Production近期发表题为“Multisource data fusion framework reveals multi-scale spatiotemporal dynamics of anthropogenic CO2 emissions in China”的文章。第一单位为长沙理工大学。
doi: 10.1016/j.jclepro.2026.147955
数据(代码)链接: https://github.com/ShanXu0927/FEMSD-framework.git
作者邮箱:210010@csu.edu.cn
标签:#碳排放格局 #多尺度分析 #时空动态 #随机森林 #多源数据融合 #空间自相关
 cover
cover本文内容速览:
- 1. 提出科学问题
- 2. 文章的主要结论
- 3. 分析过程和方法
- 4. 研究的局限性
1. 提出科学问题
1.1 研究领域现状
全球变暖是当前广受关注的环境问题,人为二氧化碳排放被公认为主要驱动因素之一。为应对气候变化,中国承诺实施“双碳”目标。相关减排措施的落实依赖于各级地方政府、工业部门及企业园区层面的具体行动,因此建立能够在多空间尺度下对人为碳排放进行可测量、可报告、可核实(MRV)的方法体系显得极为关键。传统的自下而上部门核算法(如EDGAR、ODIAC、CEADs清单)在估算中小尺度区域排放时,受限于能源质量和统计报告延迟等问题,存在较高不确定性。同时,基于遥感技术(如卫星反演的二氧化碳浓度或二氧化氮代理变量)的估算方法虽然覆盖范围广,但在全面量化多尺度时空模式及将多源数据系统融合以降低不确定性方面仍存在不足。
1.2 本文要解决的关键科学问题
针对当前高分辨率、长期且可靠的人为二氧化碳排放数据集相对缺乏的现状,文章提出并致力于解决以下问题:
- • 问题 1: 如何系统地整合多源数据(包含统计清单、卫星代理变量和社会经济数据),以建立一个能有效降低小尺度区域碳排放估算不确定性的高分辨率估算框架?
- • 问题 2: 中国人为二氧化碳排放在国家、省、市、县以及网格等多尺度下的时空演变规律是怎样的?不同区域对国家宏观减排政策的响应呈现何种空间聚集与空间异质性特征?
1.3 研究的理论/现实意义
本研究提出了一种基于多源数据融合的细尺度排放估算框架(FEMSD),生成的1公里分辨率碳排放数据集在准确性和空间细节上实现了优化。该多尺度分析揭示了隐藏在国家总量背后的排放异质性驱动因素,为精确核算碳排放和识别排放热点提供了数据基础,并为制定空间差异化的自上而下减碳政策及多中心气候治理提供了科学依据。
2. 文章的主要结论
本文通过构建细尺度排放估算框架,对中国2005至2022年的多尺度人为二氧化碳排放进行了深入评估,获得了以下关键发现:
- • 结论 1: FEMSD框架有效融合了多源数据,所生成的细尺度碳排放数据集在准确性、空间细节表现以及对已知点源的定位一致性上均优于现有的全球网格化产品。
- • 结论 2: 中国的人为二氧化碳排放在国家尺度上呈现两个阶段:2005至2013年为快速增长期,2014至2022年为波动平稳期,此转变与国家环境治理政策的强化高度吻合。
- • 结论 3: 排放空间分布维持了稳定的西低东高梯度。多尺度空间聚类分析表明,东部核心区表现为持久的高-高(HH)聚集,西部广大地区以低-低(LL)聚集为主;而在市县尺度上,排放模式的动态变化和碎片化特征更为显著。
- • 结论 4: 碳排放系统展现出高度的尺度依赖性。同一省份内部的市县可能会出现完全相反的排放轨迹,这表明统一的宏观政策实施效果会受到地方经济结构的显著调节。
3. 分析过程和方法
更加详细的复现指南可加入学术社区获取!
本研究的分析流程分为数据收集与预处理、模型构建与验证、以及多尺度时空与聚类分析三个核心环节。作者没有停留在对单一数据集的改进上,而是运用统计学标定与机器学习回归相结合的方法,将空间先验数据与多维环境和社会经济代理变量进行深度融合。
在数据准备阶段,研究选用了CEADs(中国碳核算数据库)提供的城市级统计清单作为参考基准。为了获得全球网格化先验数据,提取了EDGAR和ODIAC数据集。辅助验证与建模的数据包括OMI仪器观测的对流层二氧化氮(NO2)柱浓度、LandScan人口密度数据、NPP-VIIRS类夜间灯光数据、DEM高程数据以及从公共平台获取的发电厂和工业园区兴趣点(POI)位置信息。
作者首先对EDGAR和ODIAC数据集的可靠性进行了评估,计算其与CEADs城市级数据的相关系数和均方根误差。评估表明EDGAR与CEADs的一致性更优,因此将EDGAR确定为基础空间先验数据,而将ODIAC保留为多源融合模型中的独立空间代理变量。
随后,作者提出了FEMSD(基于多源数据融合的细尺度排放估算框架)。该框架的具体实现分为两个串联阶段。
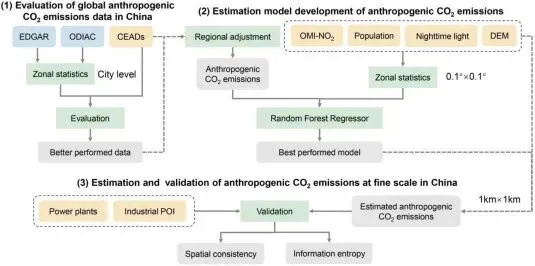 ▲Figure 1. 基于多源数据融合的人为二氧化碳排放估算框架(FEMSD)流程图
▲Figure 1. 基于多源数据融合的人为二氧化碳排放估算框架(FEMSD)流程图第一阶段是基于CEADs的区域等比例校准。为了将官方权威的统计信息整合到网格数据中,研究计算了每个城市CEADs总排放量与EDGAR总排放量的比值。以此比值作为校准系数,对该城市边界内的所有EDGAR网格进行等比例缩放。这一操作消除了EDGAR数据集在总量估算上的系统性偏差,但保留了其固有的宏观空间结构。
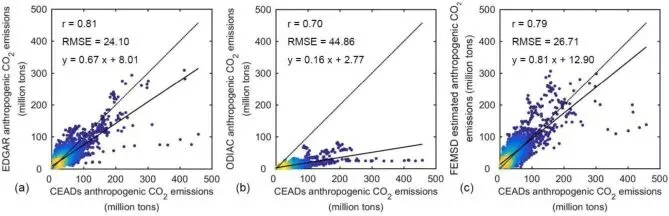 ▲Figure 2. 城市级人为二氧化碳排放量散点对比图(CEADs与EDGAR、ODIAC及FEMSD的拟合关系)
▲Figure 2. 城市级人为二氧化碳排放量散点对比图(CEADs与EDGAR、ODIAC及FEMSD的拟合关系)第二阶段采用随机森林(Random Forest)进行多源数据融合建模。以第一阶段经过校准的EDGAR数据作为因变量,选用ODIAC排放量、卫星反演NO2浓度、人口数量、夜间灯光强度、DEM高程以及经纬度作为自变量。模型训练时按照80%和20%的比例划分训练集与验证集,通过5折交叉验证结合网格搜索寻找最优超参数(旨在最小化均方根误差)。该回归模型通过学习多维特征与排放量之间的非线性映射关系,进一步优化了空间分配模式。
在结果验证和展示方面,研究不仅仅对比了总体数值误差,还引入了空间信息熵(Information Entropy)和空间一致性(Spatial Consistency)两个创新维度的评价指标。
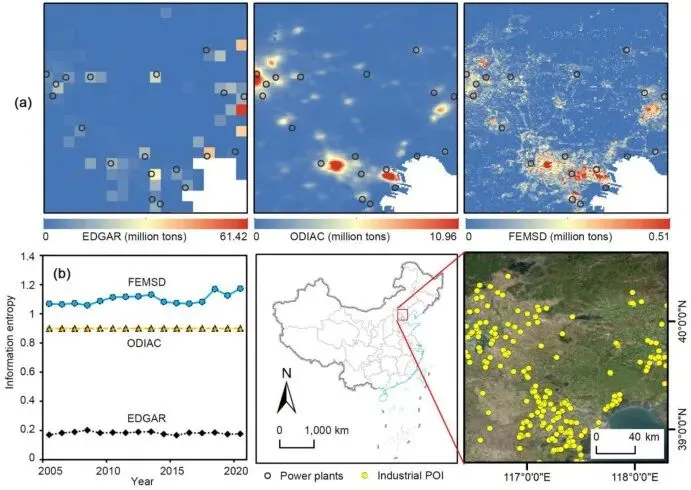 ▲Figure 3. 映射结果的准确性评估(不同数据集在局部区域的空间格局及信息熵时间序列对比)
▲Figure 3. 映射结果的准确性评估(不同数据集在局部区域的空间格局及信息熵时间序列对比)空间信息熵用于量化网格降尺度结果所捕获的空间细节丰富度,熵值越高代表空间异质性信息越丰富。分析表明FEMSD的信息熵显著高于原有产品,且具备反映年度波动的敏感性。空间一致性则用于检验高分辨率地图与真实排放源的重合度,通过计算研究区内高排放网格(85、90、95百分位数以上)覆盖发电厂或工业园区POI的比例。研究证明FEMSD在精准定位真实点源方面的能力大幅提升。
在此高精度数据集基础上,作者推进了多尺度时空演变分析。
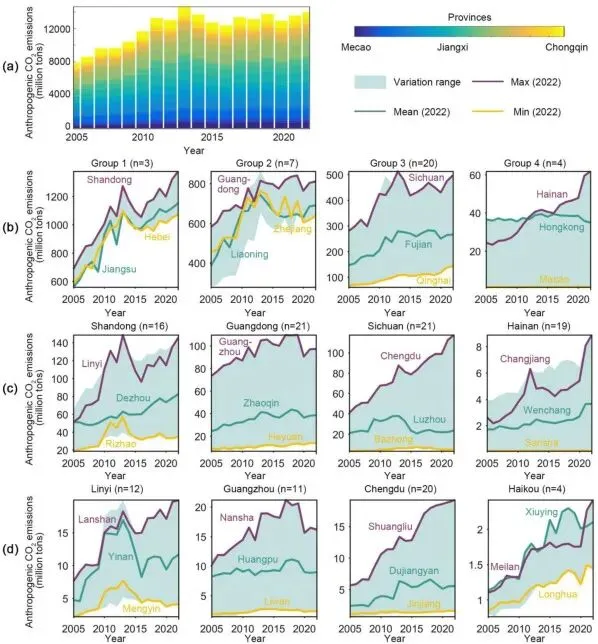 ▲Figure 4. 2005至2022年国家、省、市(部分)和县(部分)尺度人为二氧化碳排放的时间演变模式
▲Figure 4. 2005至2022年国家、省、市(部分)和县(部分)尺度人为二氧化碳排放的时间演变模式研究通过提取国家、省、市、县四级行政单元的长时间序列排放量,将各省按照排放基数划分为四组(高、中高、中、低)。这一展示方式清晰呈现了“国家总量拐点掩盖区域异质性”的现象,例如工业大省在政策约束后排放量仍维持高位震荡,而资源型省份则出现了明显的达峰回落轨迹。
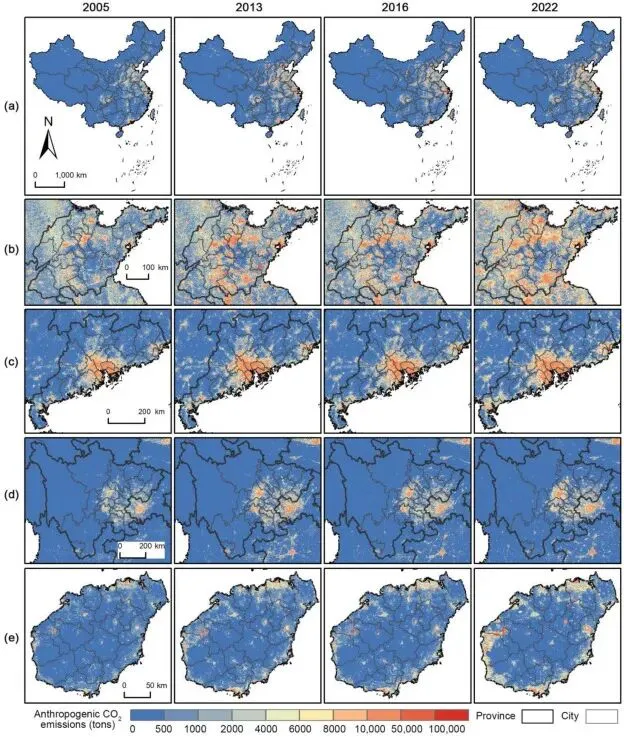 ▲Figure 5. 多尺度下的中国及典型省份(山东、广东、四川、海南)人为二氧化碳排放空间分布格局
▲Figure 5. 多尺度下的中国及典型省份(山东、广东、四川、海南)人为二氧化碳排放空间分布格局为了定量解析空间依赖特征,研究应用了局部莫兰指数(Local Moran's I)计算空间自相关性。
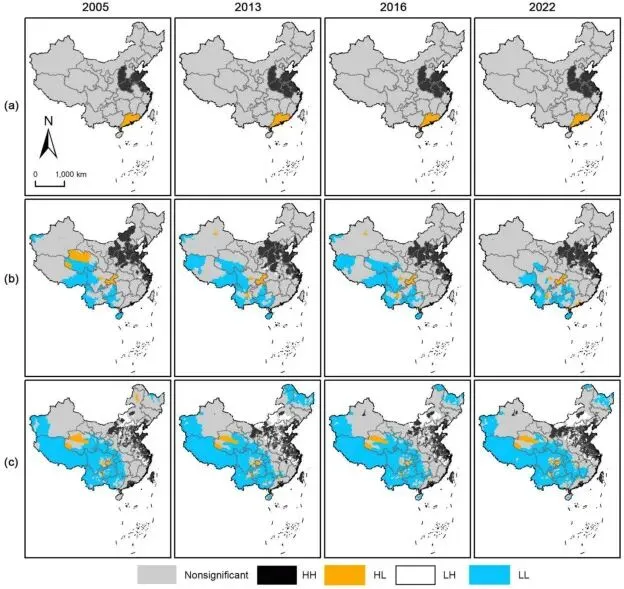 ▲Figure 6. 2005至2022年省、市、县级人为二氧化碳排放局部莫兰指数(LISA)聚类类型空间分布
▲Figure 6. 2005至2022年省、市、县级人为二氧化碳排放局部莫兰指数(LISA)聚类类型空间分布基于设定的显著性阈值,将空间单元分类为高-高(HH)、低-低(LL)、高-低(HL)及低-高(LH)聚集区。这种多尺度聚类投影使得结构锁定效应(如长三角、京津冀的持续HH聚集)和极化效应(如省会城市形成的HL孤岛)得以量化展现。通过层层递进的尺度下钻(从省到网格),这种分析逻辑证明了地理学中的可修改面积单元问题(MAUP)在碳排放治理中的体现,即宏观聚合数据会掩盖局域的关键演变过程。
4. 研究的局限性
尽管提出的FEMSD框架为推进细尺度碳监测和空间差异化气候政策制定提供了可靠的数据基础,该研究仍存在部分局限性。模型最终的准确性在很大程度上受制于作为训练基准的底层清单数据(CEADs)的质量,以及所选用的多种遥感与社会经济代理变量的代表性。由于代理变量反映的是碳排放的相关活动而非直接排放通量,在不同产业结构区域的适用性可能存在微调空间。针对未来的优化方向,文章指出可以通过整合更高频、细分行业特定以及在空间上更具动态特征的数据源(例如高频交通流量或实时用电数据),来进一步增强排放估算框架的时效性与解释能力。
如果你觉得这篇文章对你有帮助,欢迎点赞👍、收藏⭐️和分享🔗给更多的科研小伙伴们!
如果你有任何问题,欢迎加入我们的学术社群与大家讨论交流💬
最后祝大家都能多多发顶刊!!

